
Understanding 100% Precision and 100% Recall—And Why It Matters More Than You Think
Somewhere inside an investment bank, a compliance officer runs a search on a company’s recent filings. She’s looking for language around specific EBITDA adjustments. She gets 84 hits. What she doesn’t know—what the system doesn’t tell her—is that 29 other relevant filings exist. They just didn’t match her phrasing.
That gap, invisible in the moment, might never be noticed. But it can snowball, from incomplete information to a flawed analysis, which misses a red flag, and ultimately leads to non-compliant reporting, resulting in regulatory actions such as sanctions or fines.
These moments are happening every day across industries that can’t afford guesswork. From law firms to pharmaceutical labs to government watchdogs, professionals are running searches under the assumption that what they see is all there is.
More often than not, it isn’t.
Why This is Still Happening in 2025
Search systems—which underpin legal tools, financial platforms, internal document repositories—are often optimized around a tradeoff most users don’t know about.
That tradeoff sits between two technical terms: precision and recall.
Precision is about relevance. Of all the documents your system retrieved, how many were actually useful?
If 7 out of 10 results are relevant, precision is 70%.
Recall is about completeness. Of all the relevant documents in the system, how many did it actually find?
If there were 100 relevant documents, but the search only returned 80 of them, recall is 80%.
In plain terms: precision is about keeping the junk out, while recall is about ensuring that all of the gold gets in.
| a. |  |
| b. | 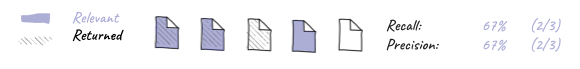 |
| c. |  |
| d. |  |
| e. |  |
Figure 1: Visualizing recall and precision with
b. 67% recall and 67% percision
c. 67% recall and 50% precision
d. 33% recall and 100% percision
e. 0% recall and 0% precision
In ideal conditions, a search tool would nail both. In reality, most systems pick one. And the consequences ripple far beyond the screen.
In legal discovery, poor precision means lawyers have to wade through hundreds of irrelevant cases that technically include the word “fiduciary,” but have nothing to do with their argument.
In manufacturing, poor recall could mean missing equipment anomalies because the system didn’t recognize that “85 degrees” and “85°C” meant the same thing in the logs from two different temperature sensors.
In medical research, if a system returns thousands of irrelevant papers, researchers lose time and focus. If it misses key studies altogether, they might pursue a path others have already proven ineffective—or worse, unsafe. As data piles up, the margin for error doesn’t just grow. It compounds.
The Recall-Precision Tradeoff is an Architecture Problem
The tradeoff between recall and precision isn’t happening because engineers are careless. At its most fundamental, all search infrastructure is about fetching needles out of haystacks. This is a function that grows in both cost and complexity as the size of the data to be searched–that is the haystack–increases.

Figure 2: Search - a Needle in a Haystack Problem
The tradeoff between recall and precision comes in when we employ cleverness to get our needles without looking through every single straw in the haystack. We use data structures and algorithms that can find most of the relevant results faster than it would take to perform an exhaustive scan over all of the documents. The problem is that “most” is, well, fuzzy. We give up some precision to get better speed. The underlying assumption is that it’s okay if some needles aren’t found, because the gains from cost reduction are larger than the losses from those missed needles.
When search was built for the internet era, the goal was to get something useful in the top 10 results. Good search was measured by users clicking something on the first page of results. When search is used in corporate, regulatory, or scientific environments, the stakes are different. Users aren’t just casually browsing. They’re building decisions, where the most critical piece of information is sometimes the smallest (and therefore easy to miss, by users as well as by the search systems themselves).
Search Architectures
There are three major types of search: boolean text search, semantic search, and knowledge graph search.
Boolean text search, or keyword search systems work well—until you also need to find synonyms and alternate phrases with the same meaning, or if you need to search over non-text documents and objects such as videos and images.
Semantic search, on the other hand, relies on tags and labels, which are applied to documents when they’re loaded into the search system (a process called labeling), and then searches for documents matching those tags and labels. More recently, vector embeddings produced by machine learning models and LLMs enable a rich encoding of features that can be searched using vector similarity search in vector databases.
In theory, this helps improve recall, because searching on similarity rather than precise text or label matching allows us to cast a wider net and retrieve more relevant results. In reality, however, this approach also brings in a lot of results that are less relevant (and sometimes even anti-relevant), which reduces precision.
Knowledge graph search is arguably the most precise, but it is hampered by its own set of challenges. Extracting knowledge from unstructured text is either manual (slow and expensive), or automated, in which it can (and nearly always does) introduce imprecision into the core data. Maintaining, updating, and searching over graphs at very large scales is an incredibly difficult problem. Graph searches depend on machine interpretation of natural language, which is itself an imprecise process (e.g. is “Mark” a name (proper noun), or a regular noun or a verb capitalized at the beginning of a sentence? Or was it incorrectly capitalized in the middle of a sentence? While a human reader can often figure this out, computers still struggle with this problem.)
Most modern systems today are typically hybrid: they try to stitch multiple approaches together by fetching candidates from multiple different search backends, and then rerank these candidates using a final relevance measure in order to return the final set of results. While this approach tends to improve recall (albeit often harming precision), the core technology is still designed and optimized for “good enough to click”.
So when is “good enough” not good enough?
In fields like law, compliance, finance, drug development, medicine, or cybersecurity, the trust that users place in the quality of their search results is often disproportionate to what these systems are designed to guarantee.
A common implicit assumption among search users is that if a document doesn’t show up in the search results, then it doesn't exist (in statistical terms, they mistake a false or unqualified negative for a true negative). Users also often assume that every single result that is returned is directly relevant, applicable, and correct, as opposed to just loosely statistically connected (mistaking an unqualified positive for a true positive). The problem with these assumptions is that they are wrong. The search tools available today don’t guarantee recall and precision, because the speed-over-precision trade-off is baked into their very core. And when incorrect or incomplete data meets deadlines, high stakes deals, or life changing medical diagnoses, the consequences often go from theoretical to material, with the potential to cause reputational, financial, and sometimes even physical harm (like in the case of a missed medical diagnosis).
At Graphium Labs, we are challenging this status quo—not by adding tiny optimizations and bandaid solutions on top of the stack of bandaid solutions that makes up today’s search infrastructure, but by rethinking the core engine entirely, so it can meet the needs of today, tomorrow, and decades from now.
Rather than relying on keyword and label matches or vector embeddings, Graphium Labs Search treats each query as a semantic graph program. That means that it doesn’t just look for text matches or vector similarity measures—it understands relationships, synonyms, nested structures, and domain-specific meaning. It can identify and resolve ambiguous interpretations and it can handle nuance. And it can do it all at scale, without sacrificing speed for quality, or quality for speed.

To be clear, our goal is to deliver both 100% precision AND 100% recall, without compromise. For any scale of data.
Graphium Labs Search is the only search platform that is built from the ground up to guarantee both recall and precision, for every single query.
If that sounds ambitious, that’s the point. For industries that can't afford to miss—or mislead—search must be held to a higher standard. Not just “fast.” Not just “relevant-ish.” Not just “good enough to click on in the first page of results.” But complete and correct.
What’s striking is how many organizations don’t even realize they’ve been living with this tradeoff. They compensate with workarounds: longer reviews, manual audits, second-guessing results. In some teams, search is so distrusted that it’s used only as a starting point—never the final word. And while each workaround feels small, they add up: in lost time and in eroded confidence; in duplicated work; in delayed insights; and in missed opportunities.
Precision and recall aren’t theoretical metrics. They are the most practical way to measure the relevance and efficiency of search and information retrieval systems, and how much they can be trusted to deliver the results that matter for your business.
If you're responsible for search systems, these questions aren’t just technical; they’re strategic. Think about your system in the context of the following questions:
Can your system explain why it returned what it did?
Can it show or account for what it missed—and why?
Can it scale without compromising quality and trust?
The answer, increasingly, can’t come from tuning. It has to come from rethinking what search is, and what it’s for, and ultimately how it’s built.
Because when the cost of getting it wrong is high, “good enough” isn’t actually good enough anymore. When the stakes are high, when you need perfect results, you should make sure your system can actually deliver with both 100% recall and 100% precision.